To Produce Transit-Oriented Discoveries, Reduce Station Data Discrepancies
Transit stations are the foundation of Transit-Oriented Discoveries. In order to promote sustainable development near transit hubs, we first need to know how many stations exist, where they are located, which agencies operate them, the lines they serve, and other relevant features. However, station information exists in multiple databases and reconciling discrepancies can be challenging. This post describes the transit station data I’m using to build my platform, identifies gaps, and explains how a popular algorithm used to compare words can bridge these gaps. I explain how I used the algorithm and evaluated my results. After reading this you’ll have a better understanding of transit station data and may also have a greater appreciation for tools like spell check.
The Data
Many transit systems around the world publish the longitude and latitude coordinates of their stops via the General Transit Feed Specification (GTFS) a standard data sharing format initially developed by Google and Tri-Met (Portland Oregon’s transit system) in the 2000s which has since become an industry standard. Data on transit stops is available via zip file or through the application program interfaces (API) of individual transit systems or GTFS aggregating platforms such as Transitland.
Transit Oriented Discoveries uses a dataset of 4,700 transit rail, bus rapid transit, and ferry stations operated by over 100 agencies. Dr. John Renne, Director of the Center for Urban and Environment Solutions at Florida Atlantic University curated this data and generously shared it with me. His data, which was compiled around 2021, uses GTFS data published on the National Transportation Atlas Database, administered by the Bureau of Transportation Statistics. It also includes the transit mode served by the station (such as heavy rail, light rail, commuter rail, etc) as well as the line(s) served by the stations. For shorthand, I’ll refer to this file as a The National Transportation Atlas, or NTA Dataset.
This project supplements the NTA with data from the 2022 Facilities Inventory from the National Transit Database (NTD) administered by the Federal Transit Administration (FTA). Transit agencies that receive Federal funds under certain grant programs are required to submit data annually and information is published after FTA contractors and staff perform data quality checks. The most recent data corresponds to Federal Fiscal Year 2022 and was published in November 2023. (Let’s call this the NTD dataset). I’ve identified around 4,000 rail, bus rapid transit, and ferry stations from this file.
I’m also using transit agency websites and station Wikipedia pages to help resolve discrepancies and provide a “ground truth”(such as the total number of stations operated by an agency). You could imagine these sources working together like a three-legged stool, or as a Venn Diagram.

Each of these sources has their strengths and weaknesses. The NTA has more stations because it includes stations from systems that are not required to report data to the NTD and it includes transit routes. The NTD data is more recent and contains information on the year the station was built, whether a station is underground, at-grade, or elevated, and the station size. (The agency and Wikipedia information isn’t available in a curated database).

Of course, we want to enjoy the best of both worlds, which means joining information on the NTA and NTD datasets together
This would be straightforward if stations on both sets shared a unique numerical identification number (sometimes called a “primary key”). But they do not. They do both contain columns with station names, but these names were manually entered by different people and do not always match. Here are examples of Chicago Transit Authority (CTA) stations with various discrepancies:

In the case of the examples shown above, it wouldn’t take much to make the little adjustments in one column or the other to get the names to match, but manually updating hundreds of station names is impractical and would likely introduce new errors.
The Math

Fortunately, there are tried-and-true algorithms that can reconcile variations in string data (in coding parlance, “strings” are a sequence of characters used to represent textual data). One algorithm is the Levenshtein edit distance method developed by Soviet and Russian mathematician Vladimir Iosifovich Levenshtein (1935-2017) also known as the “Father of Coding Theory.” Levenshtein’s distance method is is the basis for spell check, plagiarism detectors and other practical tools.
Vladimir Levenshtein, shown right.
The Levenshtein distance method takes two words and calculates how many operations are needed to change one word to the other, and vice versa. The operations are: insert, delete and substitute. For example, to transform the word “train” into “travel”, we can take “train” and substitute “i” with “v”, substitute “n” with “e”, and then insert the letter “l”. Another way is to delete the letters “i” and “n” and insert the letters “v”, “e” and “l”. Three operations is the minimum required to transform “train” into “travel” and therefore the Levenshtein Edit Distance is 3.
Here are more details on computing the distance between two words for those of you who want to try it out at home (or, if your eyes are glazing over, feel free to skip ahead). We’ll use a matrix where numbers are filled in from top left to bottom right. The size of the matrix depends on the length of the words. In the case of “train” and “travel” the matrix consists of five columns and six rows with an extra column and row with some numbers to help with the calculations. The numbers shown below represent the number of operations required to covert a “blank” word in to the words “train” or “travel.” In order to convert a “blank” into the letter “t” we insert the letter “t” which requires one edit operation. To convert a blank into “tr” we insert two letters for two operations, and so fourth. The edit distance will be the number in the last column and last row (highlighted in orange)

Now, let’s compare the “t” in “train” with the “t” in travel. They are the same letter and so none of our three operations are needed. We can represent this with a 0.

Let’s move on to comparing the “t” in “train” with the second letter in “travel” which is “r”. In this case, we could either: insert 'r' into "train" to match up to the “tr” in travel, remove 't' from "train" to match up to "r" or replace 't' in "train" with 'r' to match up to "r".
We can also display the costs of these various moves by using the numbers on the grid. When it comes to insertion, we look at the cell directly above (1,0). The value in this cell is 1 (the cost to transform “” to “r”. we add 1 for the insertion operation bringing the total cost to 2. For the deletion operation we look at the cell directly to the left (0,1). The value in this cell is 1 (the cost to transform “t” to “”) we add one for this deletion operation for a total cost of 2. Finally for substitution we look at the diagonal cell (0,0). The value of this cell is 0 (the cost to transform “” to “”) we add 1 for the substitution for a total cost of 1. Since we want the minimum cost, we add “1” to the matrix.

Skipping ahead, the final matrix with all letters compared and operations considered and quantified looks like this:

Thus equipped with the minimum edit distance and methodology, I could create matrix calculations for each of the station names in the NTA and NTD dataset, but doing so would be slower than a single-tracking “L” train in a work zone. Of course I am going to ask a computer to perform the operations for me.
The Code
I’m using Python programming language for this project and downloaded the FuzzyWuzzy library which uses the Levenshtein distance method for string matching. (A library is pre-written code that developers can use to solve common tasks and problems). FuzzyWuzzy was developed in 2011 by SeatGeek, a company that finds tickets for live sports, concerts, and theater events. SeatGeek needed a way to match event names that were similar but not exactly the same due to variations in spelling or formatting.
It might also refer to this nursery rhyme:
Fuzzy Wuzzy was a bear
Fuzzy Wuzzy had no hair
Fuzzy Wuzzy wasn’t very fuzzy, was he.
Here is how I joined information in the NTD data table to the information in the NTA table. After loading both datasets, I defined a function (i.e. set of instructions) called “get best match” which takes a row from one table and tries to find the closest matching station name in the other table using FuzzyWuzzy. It returns the best matching name and a score on how close the match is.
I then created two new columns called “matched station” which includes the NTD Facility Name and “match score” (from 0 to 100) of the best match between the station names on the two datasets. The relevant code snippet is shown below and you can find the complete code and data used on my Github page.

The L
I ran my code on a subset of the NTA and NTD datasets that included CTA stops and produced exact matches for 100 out of 145 stations for a 69% success rate (I eyeballed the station names in both sets just to be sure). The remaining station matches came back with match rates from 50% to 90%. Some stations were correctly matched, but many were not. The culprit has to do with the layout of “L” routes and the names of the stations.
The screen shot below from the CTA website shows a portion of the green, blue, and purple lines extending west from downtown. The lines run perpendicular to many cross streets and many stations on different lines share the same name:
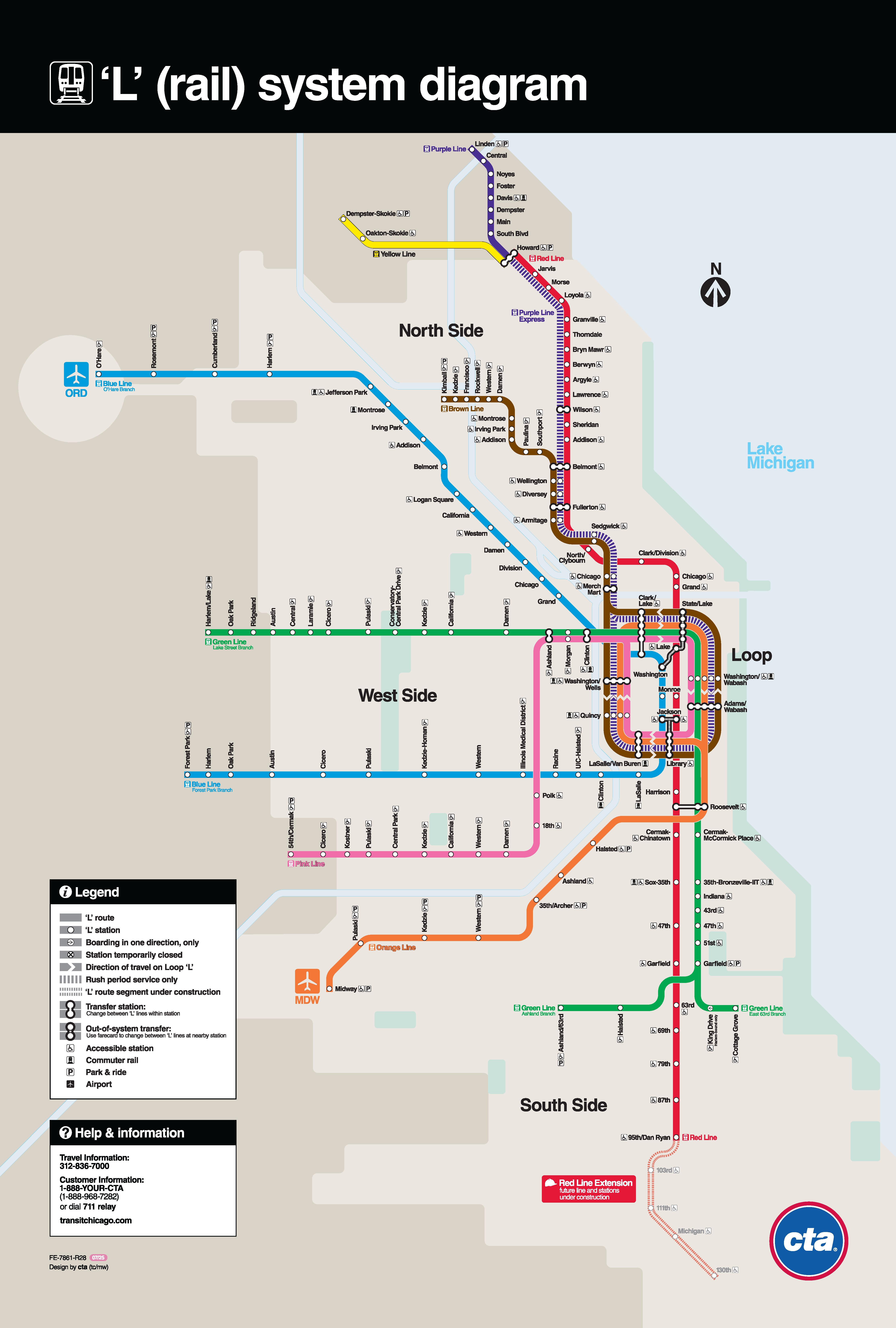
Unlike rail systems like Metro in Washington DC or BART in San Francisco (but similar to systems in New York and Philadelphia and elswewhere) CTA names stations after streets and intersections. But my code isn’t written to try to parse the difference between Ciceros or Pulaskis or Californias located on different lines so it typically assigns a single NTD Facility ID to all stations with the same name.
It took a few hours of manual inspection and reconciliation to join the data for all 145 stations. I could probably further refine my method and code to address multiple stations with the same or very similar names. In the meantime, I’ll move forward with a combination of data science and some hands-on corrections (hopefully more the former than the latter) to produce the most comprehensive and accurate station data possible. Word.